
นับตั้งแต่โลกให้ความสนใจกับ Big Data คงไม่มีใครไม่เคยได้ยินคำว่า Data Lake นี่ไม่ใช่เรื่องใหม่ และมีมานานกว่า 10 ปีแล้ว หากให้ย้อนเวลาพาท่านผู้อ่านกลับไปราว ๆ 20 ปีก่อนที่ Data Lake จะเกิดขึ้น เราคงคุ้นเคยกับคำว่า “การทำเหมืองข้อมูลหรือ Data Mining” เสียมากกว่า นั่นคือยุคแรกที่เราเริ่มขุดเหมืองเพื่อหา Insight กัน
ดูเหมือนคำว่าเหมืองข้อมูลจะค่อนข้างดูเก่ามาก ถ้าเรียกว่า Data Warehouse คงจะเข้าใจคำนี้กันมากกว่า ใช่แล้ว Data Warehouse มีมาตั้งแต่ปี 1980 เลยก็ว่าได้ เราเรียนรู้ที่จะกลั่นข้อมูลออกมาเป็นความรู้ (Knowledge) ไปใช้ต่อ เพื่อประโยชน์ทางธุรกิจ แต่ถ้า Data Warehouse มันตอบจบครบขนาดนั้น คงไม่มี Data Lake เกิดขึ้น
Data Lake เกิดขึ้นราวปี 2011 เพื่ออุดข้อจำกัดบางอย่างของ Data Warehouse เช่น การเก็บข้อมูลที่อยู่ในรูป Unstructure แบบไร้โครงสร้าง เช่น รูปภาพ, เสียงที่บันทึกต่าง ๆ เหตุผลเพื่อต้องการสกัดข้อมูลเหล่านั้นไปใช้กับการทำ AI/ML กับข้อมูลอันมหาศาล ที่เหล่านักทำข้อมูลต่างใช้ Hadoop, Spark เพื่อเล่นกับ Lake ของพวกเขา
นักทำข้อมูลมีหลายบทบาท บางทีเป็น Data Engineer บางครั้งเป็น Data Scientist หรือไม่ก็ Data Analyst พวกเขาใช้แหล่งข้อมูลที่มีโครงสร้าง หรือรูปแบบการเก็บข้อมูลที่แตกต่างกัน เช่น Data Analyst เขามักจะวิเคราะห์ข้อมูลอยู่บน Business Intelligence แหล่งข้อมูลของพวกเขามาจาก Data Mart บน Data Warehouse ซึ่งใช้ SQL ในการ Query ข้อมูลออกมา ในขณะที่ Data Scientist เขาจะเน้นทำ Machine Learning Model เป็นหลัก อาจจะใช้ SparkML ในการ Train Model ก็ได้ ซึ่งข้อมูลเหล่านี้จะเป็นไฟล์ Parquet อยู่บน Lake
เราพยายามที่จะใช้ประโยชน์จาก Data Source เดียวกัน แต่ดูเหมือนไม่ได้ตรงไปตรงมาเช่นนั้น เพราะบางครั้งเราก็ใช้ข้อมูลจาก Data Lake บางครั้งเราก็ใช้ข้อมูลจาก Data Warehouse ซึ่งช่องว่างตรงนี้ที่เป็น Gap ทำให้ Data lake มีความซ้ำซ้อน เพราะข้อมูลเดียวกันถูกเก็บซ้ำซ้อน และกระจัดกระจายหลายที่ แล้วเราจะเชื่อข้อมูลจากที่ใดว่านี่คือข้อมูลที่ถูกต้อง เป็น Single Source of Truth ปัญหานี้ ทำให้ Lakehouse เกิดขึ้น
Lakehouse คืออะไร?
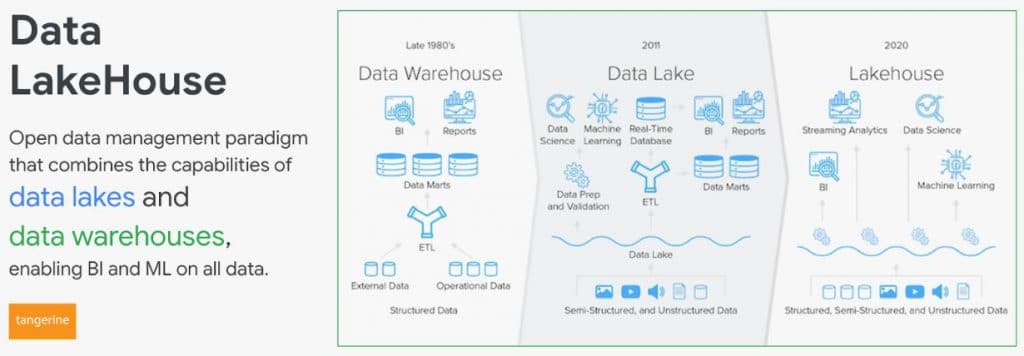
หลายท่านคงพอเดาได้ว่า Lakehouse เกิดจากการรวมคำระหว่างคำว่า Data Lake กับ Data Warehouse คือทำให้เป็นที่เดียวที่ใช้ข้อมูลจากแหล่งเดียวกัน ไม่ว่าเราจะทำ Machine Learning จะทำ BI เป็น Dashboard / Report ไม่ต้องกลัวว่า Data จะไม่ตรงกันหรือ Performance จะไม่เทียบเท่า Data Lake
ซึ่ง BigQuery ที่เราทราบกันดีว่าเก่งที่สุดในเรื่อง Cloud Data Warehouse ของโลก ณ ปัจจุบันนี้ รองรับเทคโนโลยีของ Lakehouse
BigLake คืออะไร?
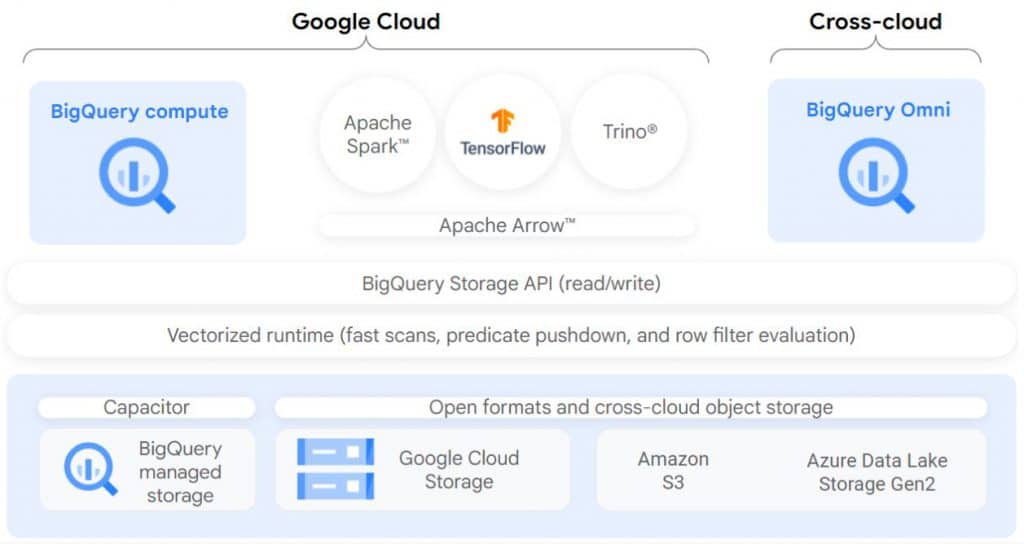
เดิมที่เจ้าตัว BigQuery เองสามารถอ่านข้อมูล Text Files จำนวนมากไม่ว่าจะเป็น Parquest, ORC, Avro, JSON, CSV ที่กระจายอยู่บน Lake มาเป็น Table บน Data Warehouse ได้เลย ซึ่งนับว่าเป็นการทำ Lakehouse อยู่แล้ว
แต่ BigLake ที่เกิดขึ้นมาใหม่บน BigQuery นั้นทำให้ Data Lake และ Data Warehouse เป็นหนึ่งเดียวกันอย่างสมบูรณ์ และยังได้เรื่องของการทำ Fine-grained Access Control หรือควบคุมสิทธิ์แต่ละคนได้อย่างละเอียด ทั้งข้อมูลที่อยู่บน Google Cloud เองหรืออยู่บน Amazon S3 และ Azure Data Lake Storage Gen2 ได้ และทำให้เราจำกัดการเข้าถึง Rows หรือ Columns ที่มีความ Sensitive ตาม PDPA ได้
ดังนั้น นักทำข้อมูลทุก Role ไม่จำเป็นต้องได้รับสิทธิ์เต็มที่ในการอ่านข้อมูลบน Data Lake พวกเขาใช้ประโยชน์ข้อมูลเหล่านี้ผ่าน BigLake บน BigQuery ก็เพียงพอ ซึ่งการจำกัดสิทธิ์แบบนี้บน Data Lake ที่ข้อมูลอยู่ในรูป Text Files หลายร้อยหลายพันไฟล์ค่อนข้างทำได้ลำบาก
วิธีเริ่มใช้ BigLake
BigLake เป็นเหมือน External Table ที่ BigQuery ไม่ได้เก็บข้อมูลอยู่บน Storage ตัวเอง เช่นเดียวกับ External Table อื่น ๆ ดังนั้นวิธีการเพิ่ม Connection ตรงนี้ไม่ต่างกัน เรามาดูขั้นตอนไปพร้อม ๆ กันเลยดีกว่า
1. สร้าง Big Lake Connection บน BigQuery Web UI
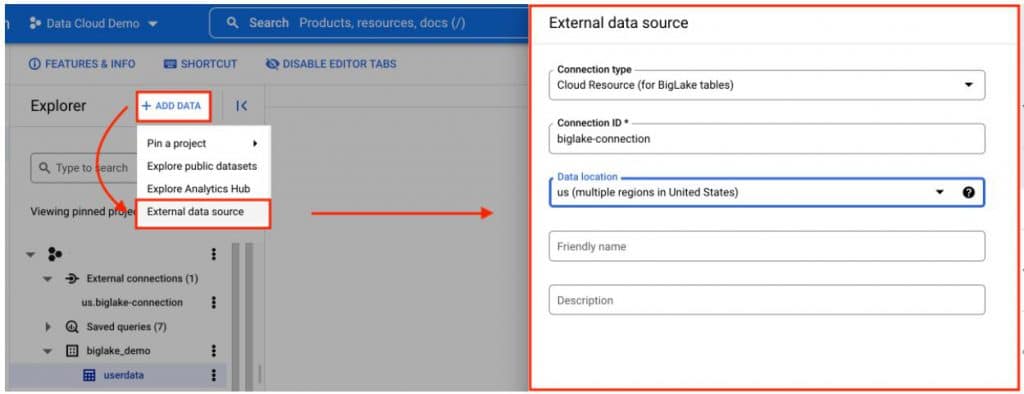
- ไปที่ + Add data เลือก External Data Source
- เลือก Connection Type เป็น Cloud Resource (for BigLake Tables)
- ตั้งชื่อ Connection ให้เรียบร้อย
2. ให้สิทธิ์ Connection ที่สร้างขึ้นใหม่ในการอ่านข้อมูลจาก Cloud Storage
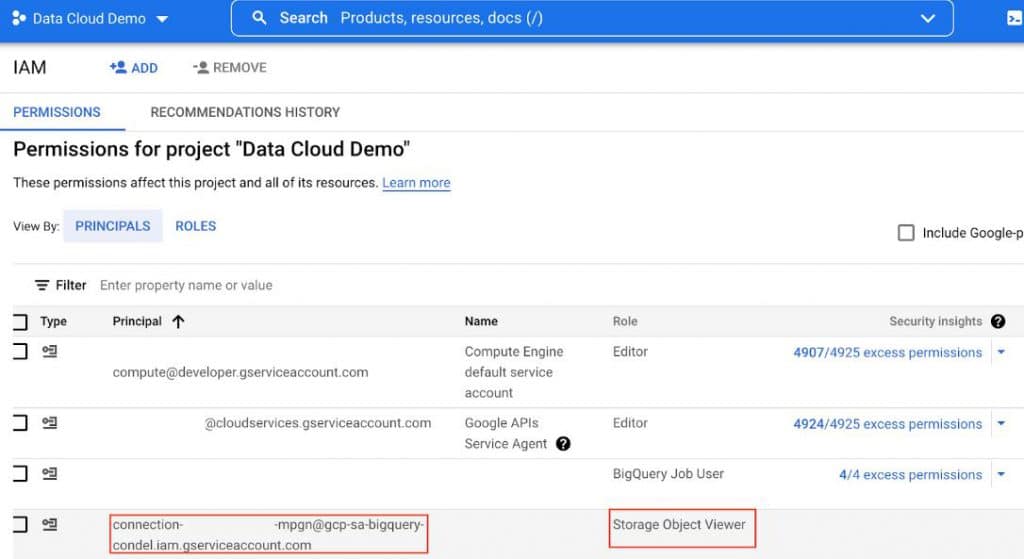
2.1 จาก Connection ที่เราสร้างขึ้นมาใหม่ Copy Service Account นี้ไป Grant สิทธิ์บน IAM
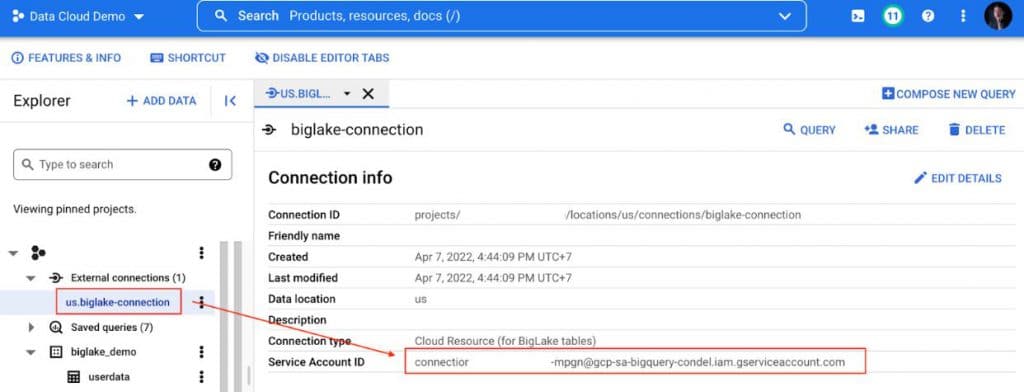
2.2 ให้สิทธิ์ Service Account นี้เป็น Storage Object Viewer
3. สร้าง BigLake Table
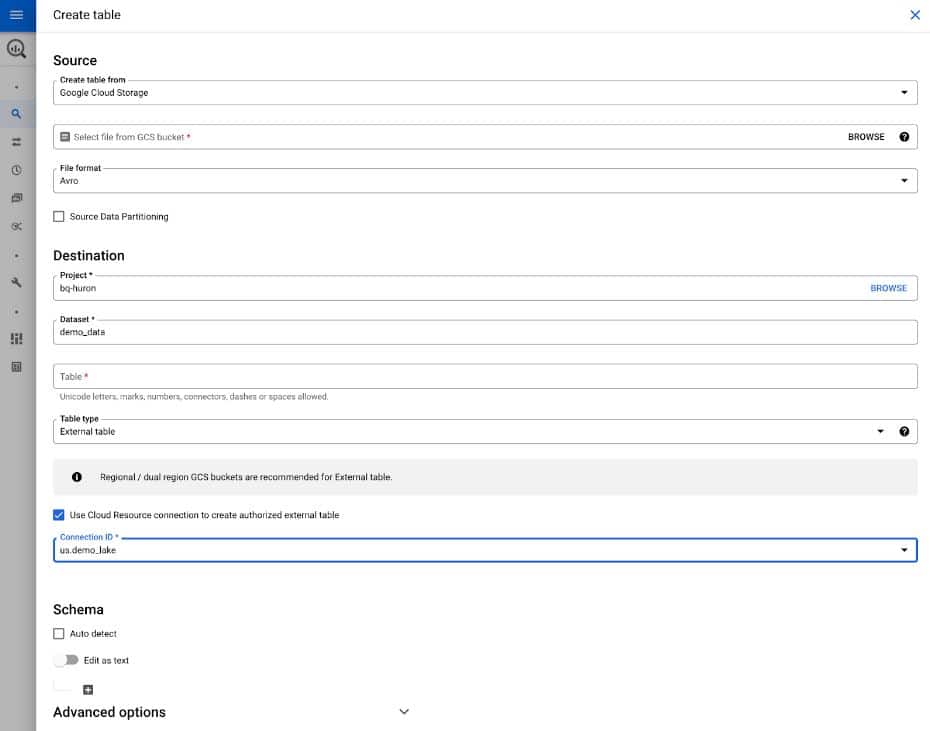
- เราสามารถไปที่ Dataset ใดก็ได้จากนั้นเลือก Create Table
- ที่ Source เลือกเป็น Google Cloud Storage แล้วกรอกข้อมูลไฟล์บน GCS
- ที่ Destination เลือกเป็น External Table จะมีช่องให้เราเลือกว่า Use Cloud Resource Connection to Crate Authorized External Table และเลือก BigLake Connection ID ที่เราสร้างขึ้นมา
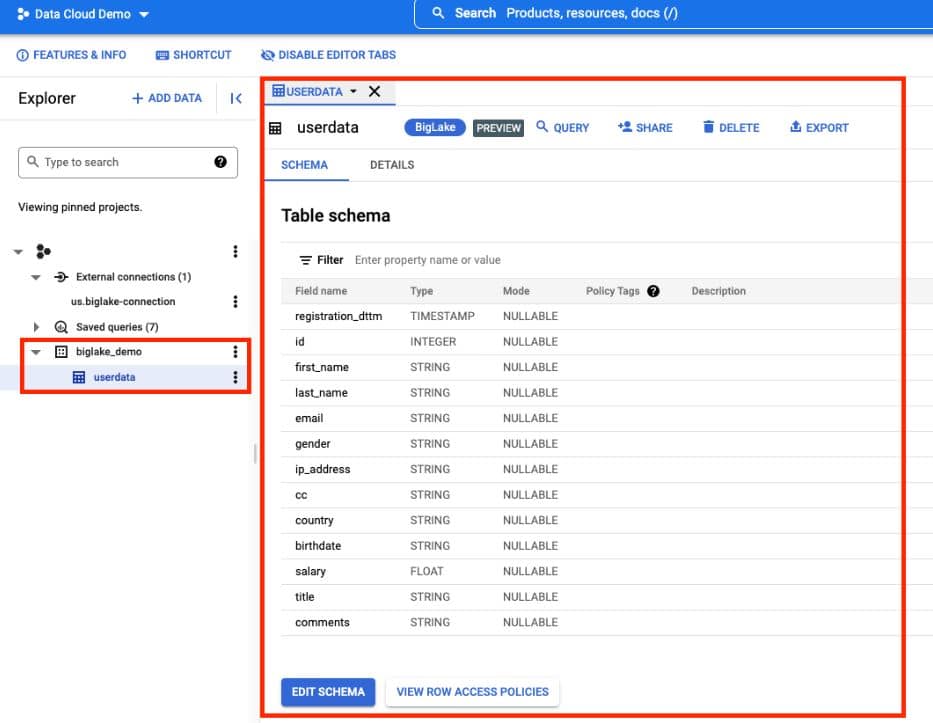
4. เราก็จะได้ BigLake Table บน Dataset ที่เราเลือกดังภาพ
ซึ่งตรงนี้เราสามารถทำ Column Level Security ได้โดย Edit Schema แล้ว Add Policy ที่สร้างขึ้น Data Catalog เพื่อจำกัดการเข้าถึง Column ที่ Sensitive เช่น เลขบัตรประชาชน, เลขบัตรเครดิตได้
เป็นอย่างไรบ้างกับการทำ Lakehouse บน Google Cloud ด้วย BigLake นั้นง่ายมาก ขั้นตอนน้อย แต่ผลลัพธ์นั้นยิ่งใหญ่ เราสามารถใช้ BigLake เป็น Data Source สำหรับทำ Model ด้วย SparkML หรือ
Query ด้วย SparkQL ก็ได้ รวมถึงยังสามารถใช้ Data Studio, Tableau, Looker หรือ BI อื่น ๆ มาต่อที่ Table นี้ได้โดยตรงอีก และมั่นใจได้ว่า Row หรือ Column ที่เรามี Policy ครอบคลุม และไม่อยากให้ผู้ไม่เกี่ยวข้องมา Query จะไม่หลุดออกไปแน่นอน เรียกได้ว่า Data Analyst และ Data Scientist ถูกใจสิ่งนี้
แทนเจอรีนเชี่ยวชาญในด้าน Digital & Cloud Technologies
ให้บริการครบวงจรระดับ Enterprise IT Solutionsทั้งองค์กรภาครัฐและเอกชนจำนวนมากให้เติบโตอย่างต่อเนื่อง
สนับสนุนต่อยอดการดำเนินธุรกิจให้สอดคล้องกับยุค Digital Transformation และครอบคลุมในทุกมิติ

