
ข่าวดีสุด ๆ สำหรับ AI Engineer หรือ Data Scientist สายที่ทำข้อมูลกับเอกสารหรือไฟล์ต่าง ๆ มากๆ คือการที่ Gemini Embedding ตอนนี้พร้อมใช้งานแบบ General Availability (GA) แล้วใน Vertex AI! และบอกเลยว่านี่คือตัวช่วยงาน RAG (Retrieval-Augmented Generation) ที่เทพมาก ๆ ครับ
Gemini Embedding คืออะไร ? ทำไมถึงเทพ ?
สำหรับคนที่ยังไม่คุ้นเคยกับคำว่า “Embedding” ผมขออธิบายง่าย ๆ ครับว่ามันคือการแปลงข้อความ (ไม่ว่าจะเป็นคำ ประโยค หรือเอกสารยาวๆ) ให้กลายเป็นชุดตัวเลข หรือที่เรียกว่า “เวกเตอร์” ครับ ซึ่งเจ้าเวกเตอร์เหล่านี้จะเก็บความหมายและบริบทของข้อความนั้น ๆ เอาไว้ ยิ่งข้อความมีความหมายคล้ายกัน เวกเตอร์ของมันก็จะยิ่งอยู่ใกล้กันในพื้นที่เวกเตอร์
ใครที่ยังไม่คุ้นเคยกับการ Embedding ผมแนะนำให้ลองปูพื้นฐานด้วย Blog นี้ก่อนนะครับ
ทีนี้พอพูดถึง Gemini Embedding มันก็คือโมเดล Embedding ที่ถูกพัฒนามาจากรากฐานของ Gemini ซึ่งเป็นโมเดลภาษาขนาดใหญ่ที่ทรงพลังที่สุดของ Google นี่แหละครับ ด้วยความเข้าใจภาษาและบริบทที่ลึกซึ้งของ Gemini ทำให้ Gemini Embedding สามารถสร้าง Embedding ที่มีคุณภาพสูงมาก ๆ และทำงานได้อย่างยอดเยี่ยมในหลาย ๆ ด้าน ไม่ว่าจะเป็น:
– RAG (Retrieval-Augmented Generation): อันนี้คือหัวใจหลักเลยครับ ! ลองนึกภาพว่าเรามี LLM ที่เก่งกาจ แต่บางทีข้อมูลที่มันรู้ก็ไม่ได้อัปเดต หรือไม่เฉพาะเจาะจงกับโดเมนของเรา RAG เข้ามาช่วยตรงนี้ครับ โดยการใช้ Embedding เพื่อค้นหาข้อมูลที่เกี่ยวข้องจากฐานข้อมูลขนาดใหญ่ของเรา (เช่น เอกสารภายใน บทความวิชาการ รายงาน) แล้วส่งข้อมูลเหล่านั้นไปให้ LLM เพื่อใช้ในการสร้างคำตอบ ทำให้คำตอบที่ได้มีความถูกต้อง แม่นยำ และเป็นบริบทเฉพาะมากขึ้นครับ Gemini Embedding ที่มีความสามารถในการดึงข้อมูลที่เกี่ยวข้องได้อย่างมีประสิทธิภาพ จึงเป็นหัวใจสำคัญที่ทำให้ RAG ทำงานได้ดียิ่งขึ้นไปอีก !
– Search (การค้นหา): ช่วยให้การค้นหามีความฉลาดขึ้น ไม่ใช่แค่ Keyword Matching แบบเดิม ๆ แต่เป็นการค้นหาจากความหมาย ทำให้ได้ผลลัพธ์ที่ตรงใจกว่าเมื่ออยู่ในลักษณะ Vector
– Classification (การจัดหมวดหมู่): จัดหมวดหมู่ข้อความได้อย่างแม่นยำ เช่น วิเคราะห์ Sentiment ของรีวิวสินค้า หรือแยกประเภทเอกสาร
– Clustering and Categorization (การจัดกลุ่มและจำแนก): จัดกลุ่มข้อความที่มีความคล้ายคลึงกัน เพื่อหาเทรนด์หรือหัวข้อที่น่าสนใจ
– Text Similarity (การหาความคล้ายคลึงของข้อความ): ใช้ระบุเนื้อหาที่ซ้ำกัน หรือตรวจจับการคัดลอกผลงาน
ความสามารถที่เหนือกว่าของ Gemini Embedding
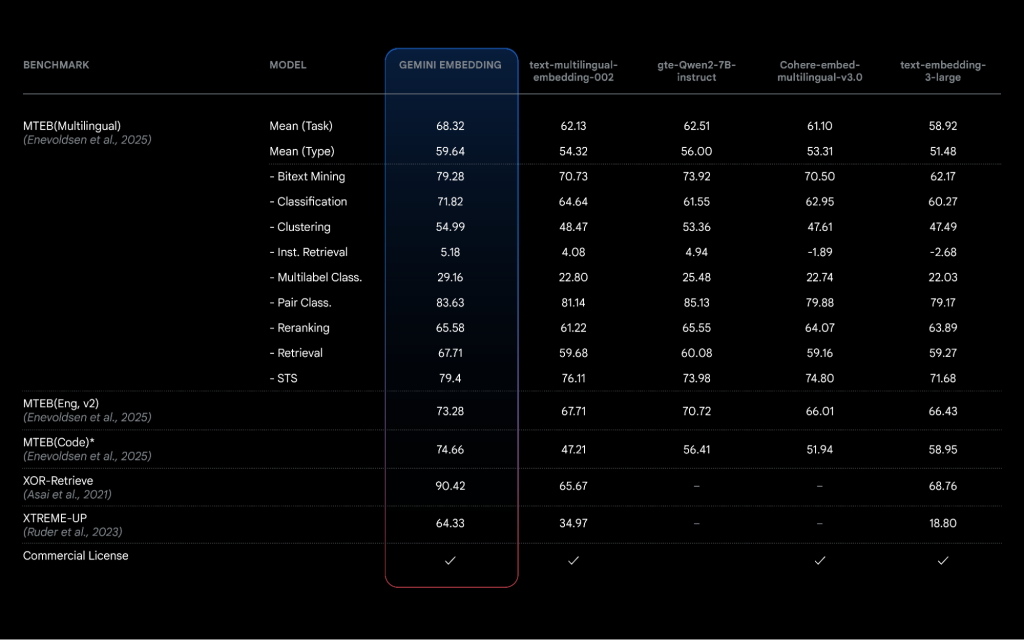
จากข้อมูลที่ผมได้สัมผัสมา Gemini Embedding (รุ่น gemini-embedding-001) โดดเด่นกว่าโมเดล Embedding รุ่นก่อน ๆ อย่างเห็นได้ชัดครับ
– เป็นโมเดล Embedding แบบครบวงจร: เป็นโมเดลแรกที่ทำผลงานได้ยอดเยี่ยมทั้งภาษาอังกฤษ ข้อความหลายภาษา และ Code! ซึ่งก่อนหน้านี้เราอาจจะต้องใช้โมเดลแยกกัน แต่ตอนนี้ Gemini Embedding เอาอยู่หมดครับ
– ประสิทธิภาพที่เหนือชั้น: ทำคะแนนได้สูงสุดบน MTEB (Massive Text Embedding Benchmark) Multilingual Leaderboard ที่มีกว่า 100 Task แซงหน้าคู่แข่งไปแบบขาดลอยเลยครับ (Mean Task Score สูงถึง 68.32 ทิ้งห่างโมเดลอันดับสองถึง +5.81) และยังทำผลงานได้ดีเยี่ยมในหลาย ๆ อุตสาหกรรม ไม่ว่าจะเป็น Retail, News, Finance, Healthcare, Legal หรือแม้แต่ Code
– รองรับ Matryoshka Representation Learning (MRL): อันนี้เจ๋งมากครับ! ช่วยให้เราสามารถเลือกขนาดของ Output Embedding ได้ตามต้องการสูงสุดถึง 3072 มิติ ทำให้เราประหยัดค่าใช้จ่ายในการจัดเก็บได้ด้วยครับ
– Input Token Limit สูงถึง 8K: ทำให้สามารถใส่ข้อความ หรือ Code ที่ยาว ๆ เพื่อสร้าง Embedding ได้
– รองรับภาษามากกว่า 100 ภาษา: ขยายขอบเขตการใช้งานให้ครอบคลุมภาษาต่าง ๆ ทั่วโลก
– Model Soup: เบื้องหลังความเทพนี้ไม่ได้มาเล่น ๆ ครับ ทีม Google ใช้เทคนิคที่เรียกว่า Model Soup ซึ่งเป็นการเฉลี่ยค่า Parameters จากโมเดลที่ Fine-tuned มาหลาย ๆ ตัว ทำให้ได้โมเดลสุดท้ายที่ Generalize ได้ดีขึ้นไปอีกขั้น เหมือนรวมร่างยอดมนุษย์กันเลยครับ
ทำไม Embedding ถึงสำคัญกับ LLM?
อย่างที่บอกไปครับ LLM นั้นฉลาดมาก แต่ความฉลาดของมันจะไร้ประโยชน์ ถ้ามันไม่สามารถเข้าถึงข้อมูลที่เกี่ยวข้องและเป็นปัจจุบันได้ Embedding คือกุญแจสำคัญที่เชื่อมโยงโลกของ LLM กับโลกของข้อมูลขนาดใหญ่ของเราเข้าด้วยกันครับ
การใช้ Embedding ในระบบ RAG ช่วยให้ LLM สามารถ:
– ค้นหาข้อมูลที่แม่นยำ: ดึงเอกสารที่เกี่ยวข้องจากฐานข้อมูลขนาดใหญ่ได้อย่างรวดเร็วและแม่นยำ โดยอาศัยความหมายของข้อความ
– ลด Hallucination: เมื่อ LLM มีข้อมูลอ้างอิงที่ถูกต้องและเป็นบริบทเฉพาะ ก็จะช่วยลดปัญหาการสร้างข้อมูลที่ผิดพลาด หรือ “Hallucination” ได้อย่างมีนัยสำคัญ
– เพิ่มความ Relevance: คำตอบที่ได้จะตรงประเด็นและมีความเกี่ยวข้องกับคำถามมากขึ้น เพราะมีข้อมูลสนับสนุนที่ดี
เริ่มต้นใช้งาน Gemini Embedding
สำหรับนักพัฒนาที่อยากลองของใหม่ ตอนนี้ Gemini Embedding รุ่นทดลอง (Experimental model) gemini-embedding-exp-03-07 ก็พร้อมให้ใช้งานผ่าน Gemini API แล้วครับ ! สามารถเรียกใช้งานได้ง่าย ๆ ผ่าน embed_content endpoint ตามตัวอย่างโค้ด Python นี้ได้เลยครับ
Python: demo_gemini_embedding.py
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
result = client.models.embed_content(
model="gemini-embedding-001",
contents="How has Tangerine's service offering?",
)
print(result.embeddings)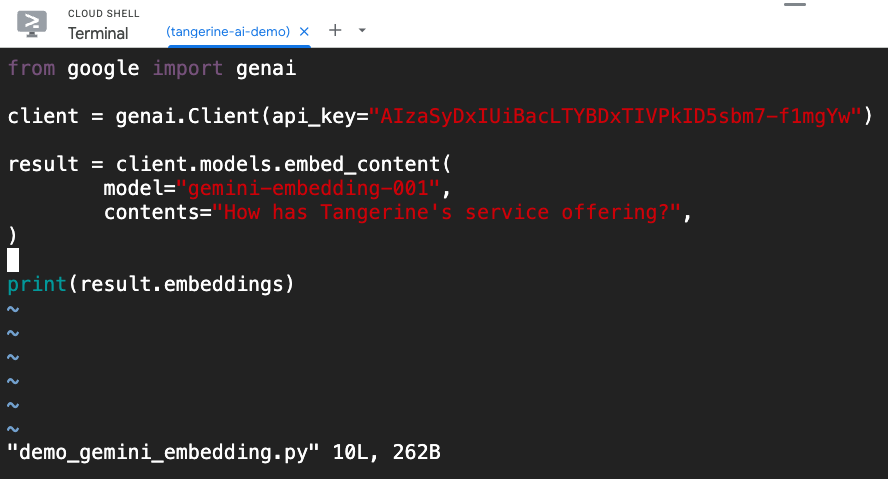
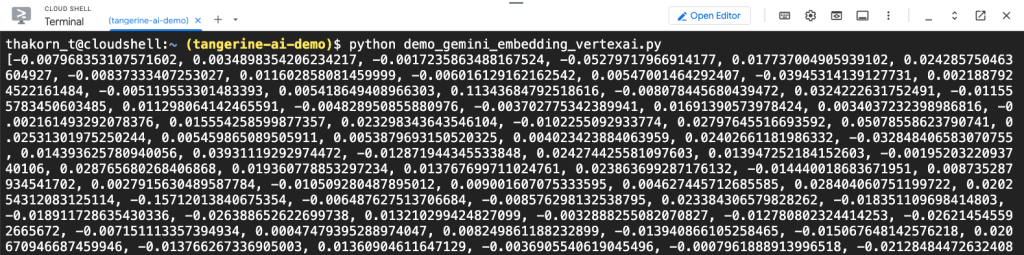
แต่ถ้าอยากใช้ตัว GA เลยที่ผมเกริ่นในบทความนี้ ปัจจุบันใช้ผ่าน Vertex AI ครับ โค้ดนี้ได้เลย
Python: demo_gemini_embedding_vertexai.py
from vertexai.preview.language_models import TextEmbeddingModel
model = TextEmbeddingModel.from_pretrained("gemini-embedding-001")
embeddings = model.get_embeddings(["Tangerine's service offering?"])
for embedding in embeddings:
vector = embedding.values
print(vector)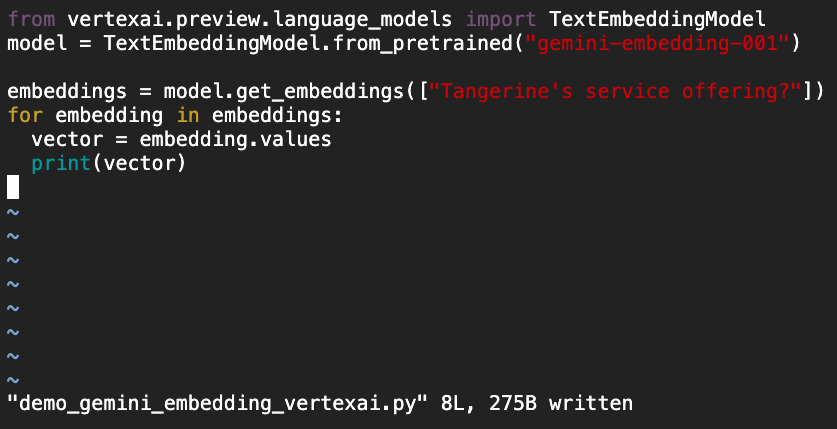
สรุป
ในฐานะที่ผมคลุกคลีอยู่กับ Google Cloud และ Data Analytics มานาน บอกเลยว่า Gemini Embedding คืออีกหนึ่งก้าวสำคัญที่จะมาช่วยพลิกโฉมการพัฒนาระบบ AI โดยเฉพาะงาน RAG ให้มีประสิทธิภาพและฉลาดล้ำยิ่งขึ้นไปอีกครับ สำหรับธุรกิจที่กำลังมองหาวิธีเพิ่มขีดความสามารถให้กับ AI ของตัวเอง การนำ Gemini Embedding มาปรับใช้เป็นอะไรที่ไม่ควรพลาดด้วยประการทั้งปวงครับ !
ถ้าใครมีคำถาม หรืออยากแลกเปลี่ยนประสบการณ์เกี่ยวกับ Gemini Embedding หรือเรื่อง Google Cloud อื่น ๆ ทักมาคุยกันได้เลยนะครับ ผมและทีม Tangerine ยินดีให้คำปรึกษาเสมอครับ
ติดต่อ แทนเจอรีน ได้เลยที่ marketing@tangerine.co.th หรือโทร 094-999-4263

