จากบทความที่แล้วที่ได้เห็นความสามารถในการเขียน Python บน BigQuery Studio กันบ้างแล้ว และตามที่ติดกันไว้ในเรื่อง BigQuery DataFrames เอาใจคนรัก Pandas กับ BigQuery เพื่อไม่ให้เป็นการเสียนาฬิกา… เอ้ย!!! เวลา ไปเริ่มกันเลย
บทความนี้จะใช้ BigQuery Studio ในการอธิบายเรื่องราวของ BigQuery DataFrames บน Pandas หากใครใดหลงมา ยังไม่ได้อ่านเรื่อง BigQuery Studio สามารถอ่านได้ที่บทความนี้

BigQuery DataFrames คืออะไร ?
ต้องท้าวความนิดนึงสำหรับนักเล่นแร่แปรข้อมูลส่วนใหญ่จะรู้จัก Pandas DataFrames กันอยู่แล้ว เพื่ออ่าน CSV, Excel, Parquet หรือดูดข้อมูลจาก Database อื่น ๆ แต่หากเล่นกับข้อมูลบน Data Lake หลายคนก็อาจใช้ PySpark กันเพราะยืดหยุ่นในเรื่อง Memory มากกว่า
ซึ่ง BigQuery DataFrames ก็จะมีความยืดหยุ่นคล้าย ๆ กับ RDD บน PySpark คือสามารถรองรับ Dataset ที่มีขนาดใหญ่ได้อย่างมีประสิทธิภาพไม่กระทบต่อ Memory บนเครื่องประมวลผลที่มีจำกัดได้ (แต่หากใช้ Google Cloud ก็ไม่ต้องกังวลหรือ Resource ที่จำกัดเลย 😀)
ที่แตกต่างคือ Spark นั้นต้องการ Cluster ที่มาประมวลผลขนานกันซึ่งต้องจัดการ Clusters ต่าง ๆ ขณะที่หากใช้ BigQuery นั้นไม่ต้องจัดการอะไรเลย
เกริ่นมายาว… สรุปว่า BigQuery DataFrames คืออะไรกันแน่ล่ะ ? ถ้าให้สรุปสั้น ๆ คือ Python API ตัวหนึ่ง ที่ลักษณะหน้าตาเหมือน Pandas เรียกสั้น ๆ ว่า BigFrames
โดยการใช้งานแค่เปลี่ยนจาก Import Pandas as pd เป็น Import bigframes.pandas as bf เดี๋ยวลองมาดูตัวอย่างโค้ดบน BigQuery Studio กัน
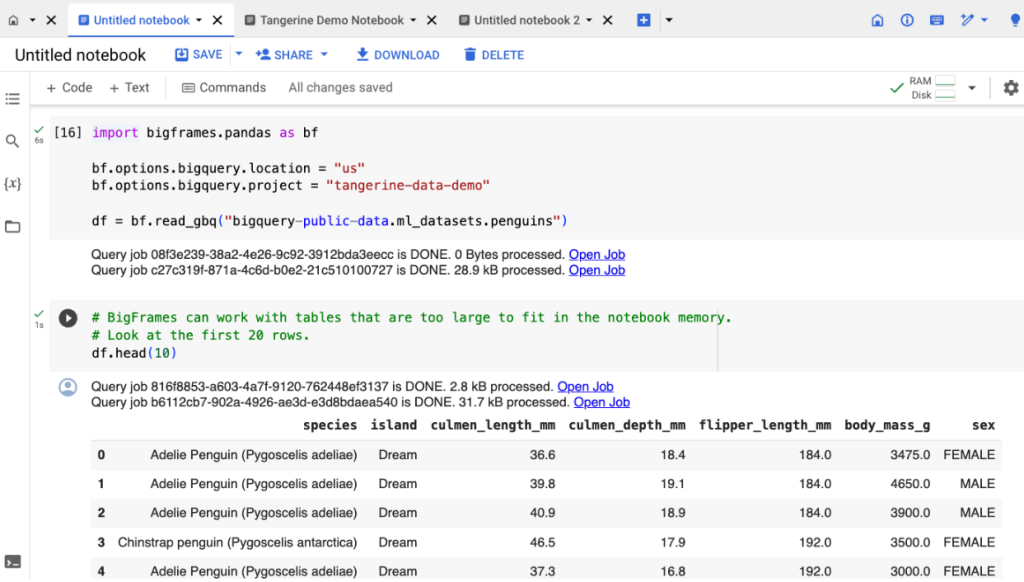
จะเห็นว่าผลลัพธ์มีความเป็น DataFrames คล้ายคลึงกับ Pandas แต่ต่างกันที่ ณ จังหวะแรกจะยังไม่ได้มีการ Transfer Data จาก BigQuery มาเก็บในตัวแปร df จนกระทั่งถึงจังหวะที่ต้องเรียกดูข้อมูลตรง df.head(10) เจ้า APIs ตัวนี้ก็จะแปลงเป็น Query ไปคุยกับ BigQuery แล้วจึงเอาแต่ผลลัพธ์มาโชว์
ดังนั้นมันค่อนข้างยืดหยุ่นมาก ๆ หากมีสัก 10 ล้าน Records หรือใหญ่สัก 10 TB ที่ Memory เอาไม่อยู่หรือเอาอยู่ก็อาจปั่นข้อมูลช้ากว่าที่ส่งไปให้ BigQuery คำนวณมาให้
ซึ่ง BigFrames จะมาพร้อมกับ APIs สองตัวคือ
- bigframes.pandas เป็น APIs ที่ใช้ร่วมกับ Pandas ดังภาพตัวอย่างข้างต้น
- bigframes.ml เป็น APIs ที่ช่วยทำ Model แบบใน Scikit-learn บน BigQuery
พอรู้จักกับ APIs แล้วก็พอจะเดาแล้วใช่ไหมว่าหากใช้ BigQuery Studio เขียน Python ก็น่าจะทำโมเดลได้ง่ายขึ้น เช่น การเตรียมข้อมูล Feature Engineering แล้วมาเรียกใช้ bigframes.ml
Benefit จากการใช้ BigQuery DataFrames
ก่อนที่จะไปลงโค้ดกัน มาดูประโยชน์แต่ละด้านจากการใช้ BigFrames กันก่อน
- Scalability: BigQuery DataFrames มีความยืดหยุ่นและสเกลได้ในการจัดการ Dataset ขนาดใหญ่โดยใช้ประโยชน์จากสถาปัตยกรรมของ BigQuery ที่เป็น Distributed Computing
- Performance: BigQuery DataFrames มีประสิทธิภาพสูงในการ Query ที่ซับซ้อนได้อย่างรวดเร็วในการทำ Data Manipulation
- Ease-of-use: ใช้ง่าย เพราะคนที่ใช้ Pandas DataFrames คุ้นเคยกันอยู่แล้ว มี Method หรือ Properties ที่คล้ายกัน เพราะฉะนั้น Data Scientist หรือ Data Analyst แทบจะใช้เป็นในทันที
และถ้าพูดในมุม Key Highlight ของ BigFrames มีดังต่อไปนี้
- Read Data from BigQuery Tables and Queries: แค่ใช้ function read_gbq() ก็สามารถอ่าน BigQuery Tables หรือ Execute SQL เข้า DataFrames ได้อย่างง่ายดาย
- Perform Data Transformations: สามารถทำ Data Transformation แบบที่ทำกับ Pandas ได้เช่น filter(), groupby(), fillna() หรือ aggregate() เป็นต้น
- Export Data to Various Formats: สามารถบันทึกข้อมูลจาก DataFrames เป็น Format ต่าง ๆ ได้เหมือน Pandas เช่น CSV, JSON และ Parquet
- Integrate with Scikit-learn: สามารถใช้ bigframes.ml ในการใช้ Scikit-learn ทำ Machine Learning Task กับข้อมูล BigQuery ได้โดยตรง
จะเขียน BigFrames ต้องทำอย่างไร ?
อย่างแรกคือต้องคุ้นเคยกับการใช้ Pandas ก่อนเพราะ Syntax ในการ Data Manipulation นั้นเหมือนกัน ต่างกันที่ตอนประกาศ Read ข้อมูลเบื้องต้นต้องใช้ Functions read_gbq() ดังตัวอย่างนี้
import bigframes.pandas as bpd bpd.options.bigquery.project = “<your_gcp_project_id>” df1 = bpd.read_gbq(“project.dataset.table“) df2 = bpd.read_gbq(“SELECT a, b, c, FROM `project.dataset.table`”)
ซึ่งสามารถศึกษาจาก Document นี้ได้เลย https://cloud.google.com/python/docs/reference/bigframes/latest
และสามารถดู Properties ต่าง ๆ ในการ Manipulate Data ได้จาก Document นี้ https://cloud.google.com/python/docs/reference/bigframes/latest/bigframes.dataframe.DataFrame
แล้วถ้าจะทำ Machine Learning ด้วย BigFrames ต้องทำอย่างไร ?
สำหรับ Machine Learning นั้นไม่ยากหากคุ้นเคยกับ Scikit-learn Syntax ก็แทบจะเหมือนกัน ขออนุญาตยกตัวอย่างที่ต่อยอดจากบทความก่อน ที่ใช้ Penguin Dataset มาทำโมเดลทำนาย Species ของ penguin โดยใช้ Feature ที่อยู่ใน Public Data ชุดนี้
# ผู้เขียน import bigframes api มาใช้เท่าที่จำเป็นโดยเริ่มต้นจาก bigframes.pandas import bigframes.pandas as bf # ใช้ RandomForestClassifier เป็น Classifier model ในการทำ M และใช้ train_test_split ในการแบ่ง data เพื่อวัดผล และใช้ accuracy_score เป็น metric ในการวัดความถูกต้องของ model from bigframes.ml.ensemble import RandomForestClassifier from bigframes.ml.model_selection import train_test_split from bigframes.ml.metrics import accuracy_score bf.options.bigquery.location = “us” bf.options.bigquery.project = “<your_gcp_project_id>” # อ่านข้อมูล น้องเพนกวิน จาก public dataset df = bf.read_gbq(“bigquery-public-data.ml_datasets.penguins”) # เลือก columns ที่เป็น features และ target ในการ predict X = df[[‘island’,’culmen_length_mm’,’culmen_depth_mm’,’flipper_length_mm’,’body_mass_g’, ‘sex’]] y = df[‘species’] # แบ่ง train/validate เพื่อวัดผลในตอนท้าย X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Train RandomForest แบบง่ายๆ model = RandomForestClassifier() model.fit(X_train, y_train) # วัดผล model predictions = model.predict(X_test) accuracy = accuracy_score(y_test, predictions) print(“Accuracy:”, accuracy)
จากนั้นมาดูผลลัพธ์จากการรันโมเดลจะเห็นว่าตัว Random Forest จาก bigframes.ml ได้ Accuracy สูงถึง 94.2% ด้วยการสร้าง Model ที่ค่อนข้าง Simple โดยยังไม่ได้ทำ Feature Engineering และ Hyper Parameter Tuning เลย เพราะเบื้องหลังของการ Train Model นี้เป็น BigQuery ML ที่ทำ Auto Tuning ให้เบื้องต้นอยู่แล้ว
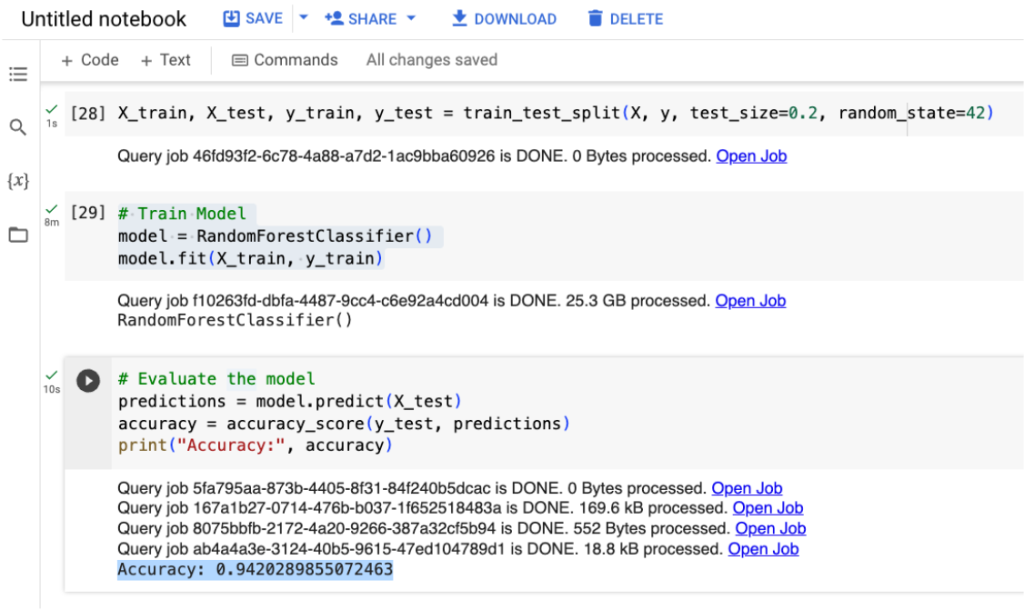
จากภาพนี้สังเกตว่าสามารถกด Open Job เพื่อดูรายละเอียด Jobs เบื้องหลังที่ BigFrames เข้าไปคุยกับ BigQuery เป็น SQL ได้ และต่อไปดู Job ในขั้นตอน model.fit กัน
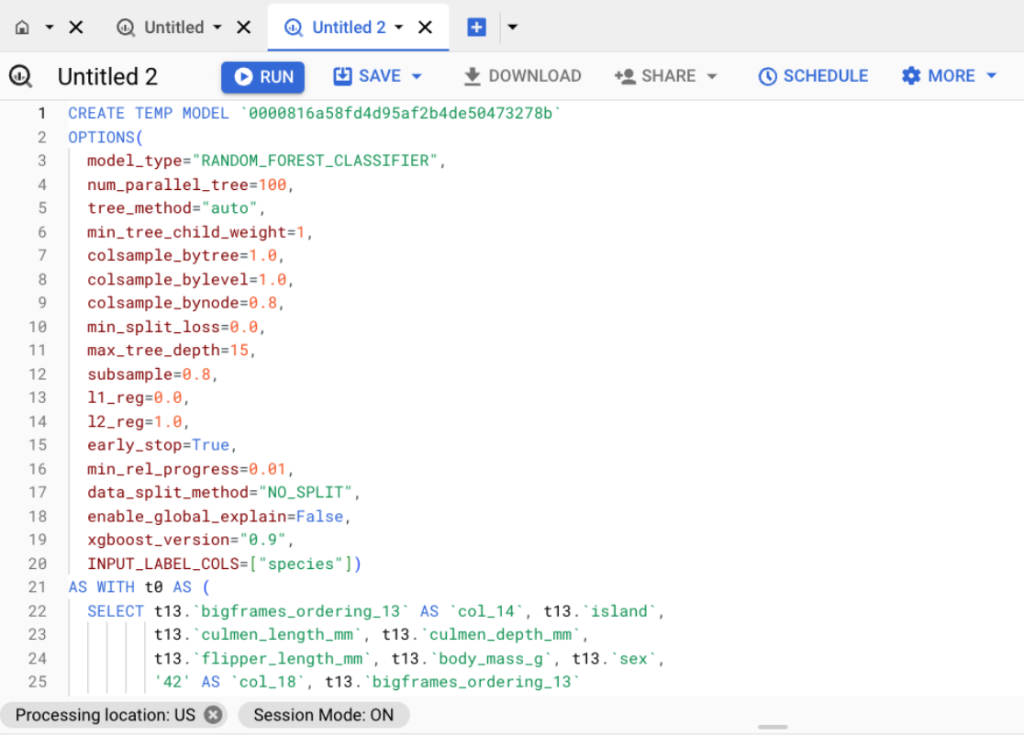
เมื่อกด Open Job จะพาไปสู่หน้า BigQuery เผยให้เห็น Query เบื้องหลังที่ BQML กว่า 100 บรรทัดที่ BigFrames Generate มา แสดงให้เห็นว่าการเขียน BigFrames ช่วยประหยัดเวลาในการทำ Query ค่อนข้างมาก และถ้าอยาก Config Hyper Parameter ก็สามารถดู Document ของ RandomForestClassifier ได้เลย
และสิ่งที่สามารถทำต่อหลังจาก model.fit() มาก็หลากหลาย ไม่ว่าจะเป็น การเอา Model กลับไปเก็บที่ BigQuery ด้วย model.to_gbq() หรือ model.register() จะ Register Model ไปไว้บน Vertex AI เพื่อพร้อมทำเป็น API Endpoints ให้ทีมอื่น ๆ มาใช้ต่อก็ได้ โดยสามารถดูข้อมูลเพิ่มเติมที่ RandomForestClassifier Document
นอกจากนี้ยังสามารถทำ Model อื่น ๆ ได้อีกมากมายรวมถึง Model ด้านภาษาอย่าง LLM (Large Language Model) ที่เป็น Generative AI บน BigQuery หรือ ทำ Preprocess Data, ML Pipeline ก็ได้ โดยสามารถดูข้อมูลเพิ่มเติมที่ Document นี้เลย
Conclusion
เรียกได้ว่า BigFrames + BigQuery Studio เป็น Game Changer ในการเขียน Python จริง ๆ หวังว่าทุกคนจะสามารถประยุกต์ใช้ BigFrames แทน Pandas DataFrames เพื่อรีดประสิทธิภาพของ BigQuery ออกมาได้มากที่สุด และหากต้องการใช้ Google Cloud แบบรู้ลึก รู้จริง ก็สามารถติดต่อทีม Google Cloud by Tangerine เพื่อช่วยองค์กรของทุกคนได้