ในการทำ Data Warehouse สิ่งสำคัญที่จะลำเลียงข้อมูลมาลงเหมืองข้อมูลได้ ก็คือ Data Pipeline ซึ่งส่วนใหญ่จะเป็นข้อมูลที่เป็นลักษณะ Incremental คือมี Record เกิดขึ้นใหม่ เช่น Sale Transactions หรือ Logs ต่าง ๆ ก็จัดการได้ไม่ยากนัก แต่ Challenge ที่มักพบกับข้อมูลที่ไม่ได้เป็น Incremental คือข้อมูลที่ไปแก้ใน Record เดิม ๆ เช่น ราคาหุ้นที่เปลี่ยน, แต้มสมาชิกคงเหลือในบัญชี ที่จำเป็นต้อง Sync ระหว่าง Database ต้นทาง และ Data Warehouse ใน Record เดิมเช่นกัน เพราะจะทำให้ Data มีความแตกต่างจนอาจทำให้เกิดความผิดพลาดได้ ซึ่งเราจะแก้ปัญหานี้ด้วยกระบวนการ CDC
CDC คืออะไร ?
CDC ย่อมาจาก Change Data Capture เป็นกระบวนการในการ Identify และ Track ข้อมูลที่มีการเปลี่ยนใน Database ในลักษณะ Real-time / Near-real-time หรือขึ้นอยู่กับการตั้งค่า Refresh Rate ของผู้ใช้โดยอาศัยการตรวจจับการเปลี่ยนแปลงที่เกิดขึ้นบน Database ต่าง ๆ เช่น การเพิ่ม ลบ หรือแก้ไขข้อมูล
CDC มีกี่แบบ ?
CDC จะมีสองแบบหลัก ๆ คือ
- Log-based CDC: เป็น CDC ที่อ่านค่าการเปลี่ยนแปลงจาก Log ซึ่ง Database Log จะบันทึกทุกค่าที่มีการเคลื่อนไหวบนฐานข้อมูล
- Trigger-based CDC: เป็น CDC ที่อ่านค่าที่เปลี่ยนจากการ Trigger ที่ยิงเข้ามาว่ามีการเปลี่ยนแปลงเกิดขึ้น
CDC ใช้ใน Use Case ใด มีประโยชน์อย่างไรบ้าง ?
CDC มักใช้ในหลากหลาย Use Case เช่น
Data Replication
การ Sync ระหว่าง Database และ Applications ต่าง ๆ ซึ่งมีประโยชน์อย่างมากในการทำ Disaster Recovery, Load Balancing โดยให้ลองจินตนการว่า Database ล่มไป ทำให้ธุรกิจหยุดชะงัก ทีมวิศวกรก็เร่งมือเต็มที่ ที่จะเอา Database ขึ้นระบบอีกครั้ง ปรากฎว่า Backup File ล่าสุดนั้นเป็นของเมื่อวาน ขณะที่ข้อมูลวันนี้มีการเปลี่ยนแปลงไปมากมายแล้ว สำหรับเคสนี้ก็สามารถใช้ Database Log มา CDC ร่วมกับ Backup File มา Replicate Data ให้กลายเป็นข้อมูลปัจจุบันเพื่อขึ้นระบบต่อได้
Data Warehousing
การโหลดข้อมูลเข้าสู่ Data Warehouse หากนำกระบวนการ CDC เข้ามาจะทำให้ข้อมูลต้นทาง/ปลายทางตรงกัน ได้ความเป็น Single Source of Truth มากขึ้น มั่นใจในข้อมูลมากขึ้น
Data Integration
รวบข้อมูลจากหลากหลาย Source ให้เป็น Single view การทำ CDC จะทำให้ได้ข้อมูลที่เป็นปัจจุบันเหมือน Database ต้นทาง ส่งผลให้ข้อมูลมีความแม่นยำ น่าเชื่อถือ และทำ Report เพื่อตัดสินใจได้ดีขึ้น
Auditing
เราสามารถ Track การเปลี่ยนแปลงของข้อมูลเพื่อวัตถุประสงค์ต่าง ๆ เช่น การ Audit ทำให้เราทราบว่าใครเป็นคนเพิ่ม ลบ หรือเปลี่ยนแปลงข้อมูลนี้
สิ่งที่ต้องระวังในการใช้ CDC
แม้ว่า CDC มีประโยชน์มากมาย แต่ก้มีข้อระวังต่าง ๆ ที่ควรทดไว้ในใจ เช่น
CDC อาจมีความซับซ้อนในการตั้งค่าและจัดการ
โดยปกติ Database ปัจจุบันจะมี Feature สำหรับการทำ CDC มาให้ แต่ถ้าเราไม่คุ้นเคยในการจัดข้อมูล CDC อาจจะลองใช้เครื่องมือสำเร็จรูป เช่น Datastream, Data Fusion, Fivetran เป็นต้น
CDC อาจมีผลกระทบต่อ Performance ของ Database
หากเราเปิด CDC เพื่อบันทึกการเปลี่ยนแปลงของข้อมูลที่มีขนาดใหญ่มากอาจะทำให้ Database ต้องมาคอยเขียน Logs ขนาดใหญ่เช่นกัน ซึ่งส่งผลต่อประสิทธิภาพการทำงานของฐานข้อมูลด้วย ดังนั้นเราจึงต้องตั้งค่า Database ให้เหมาะสมเพื่อลดผลกระทบที่จะเกิดขึ้น
CDC ไม่ใช่ทุกอย่าง
เรามักคิดว่าทุกอย่างต้อง Sync Real-time ถึงจะดี แต่ Real-time ไม่ใช่ Right-time เราจึงต้องหาจุดที่เหมาะสมกับข้อมูลเราในการ Sync เพราะมันมีความซับซ้อนต่อการจัดการที่แลกมา และแม้ว่าข้อมูลของเราจะ Sync กัน แต่ก็ไม่ได้รับประกันว่าข้อมูลของเราจะถูกต้องเสมอไป ดังนั้นเราต้องมีกระบวนการในการตรวจสอบความถูกต้องของข้อมูลอีกครั้ง เช่น การทำ Data Quality
CDC บน Google Cloud เป็นอย่างไร ?
แม้ว่า CDC จะมีความซับซ้อนในการจัดการ แต่หากเราพัฒนา Platform บน Google Cloud จะทำให้การทำ CDC เป็นเรื่องง่าย เพราะบน Google มีเครื่องมือที่อำนวยความสะดวกในการทำ CDC อยู่แล้ว คือ Datastream
Datastream คืออะไร ?
Datastream คือ Service ประเภท Serverless ที่ง่ายในการจัดการข้อมูล CDC และ Replicate Data ซึ่งสามารถ Synchronize ข้อมูลกับแบบ Heterogeneous Databases (Database คนละยี่ห้อ คนละสถาปัตยกรรมกัน) รวมถึง Application ที่ต้องการรับข้อมูลแบบ CDC ด้วย
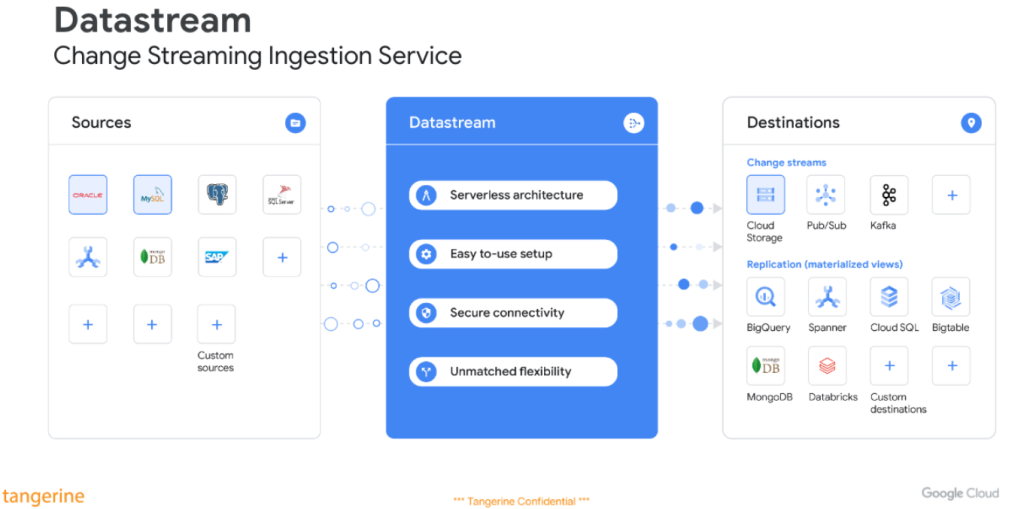
ซึ่ง Roadmap ของ Datastream จะรองรับ Source ที่หลากหลาย เช่น Oracle, MySQL, AlloyDB, PostgreSQL Server, Cloud Spanner, MongoDB, SAP และ Sync ไปยัง Cloud Storage, Pub/Sub, Kafka, BigQuery หรือ Database อื่น ๆ บน Cloud ได้
ซึ่งในปัจจุบัน ณ วันที่ 5 Jul 2023 มี Source ที่รองรับคือ Oracle, MySQL, AlloyDB, PostgreSQL, Server และ Destination เป็น Cloud Storage และ BigQuery เท่านั้น
Datastream จะ Stream ข้อมูลจากต้นทางสู่ปลายทางด้วยกัน 2 วิธีคือ
- CDC เป็นการตรวจจับข้อมูล Change แบบ Real-time
- Backfill เป็น Stream Historical Data (หรือ Existing Data) จากต้นทางทั้งหมดลงปลายทาง
Datastream รองรับ network connectivity ที่หลากหลาย ดังนี้
- IP Allowlisting
- Forward SSH Tunnel
- Private Connectivity (VPC Peering)
จุดเด่นของ Datastream คือ
- Serverless เราเรียกใช้ Datastream ได้ทันที โดยไม่ต้อง Provinsioning Infrastructure ขึ้นมา
- Easy-to-use ใช้ง่ายไม่ต้องเขียนโค้ด ไม่ต้องสร้าง Pipeline เพราะเป็น Service สำเร็จรูปแล้ว
- Reliable Datastream การันตรีที่ SLA 99.99% ไม่ต้องกังวลแม้ Workloads จะสูง
- Scalable สามารถ Scale เพื่อรองรับ Load ได้เอง ตามแบบฉบับ Serverless
- Pricing ด้วยความเป็น Cloud-native จึงราคาถูกมาก เมื่อเทียบกับผลลัพธ์ที่ได้
Data Analytics Platform with CDC
หากให้ทุกท่านเห็นภาพมากขึ้นในการทำ Data Analytics Platform ด้วย Datastream ผู้เขียนได้มี Architecture ตัวอย่างดังนี้

สังเกตว่าการลำเลียงข้อมูลเราใช้เพียง Datastream ก็สามารถลง BigQuery ได้แล้วเป็นอันเสร็จสิ้น แต่ถ้าหากต้องการ ELT ด้วยก็สามารถใช้ Dataform ที่เป็นเครื่องมือฟรีบน BigQuery เขียน SQLX ก็ได้
หากต้องการทำ Machine Learning ก็สามารถทำบน BigQuery ในตัวหรือที่เรียกว่า BigQuery ML ก็ได้ แต่หากทีม Data Scientist ต้องการทำ Model ด้วย Python บน Jupyter Notebook ก็สามารถใช้ Vertex AI Workbench ในการพัฒนา Modeling ได้
และในส่วนสุดท้ายคือการออก Report / Dashboard เราสามารถใช้ Google Sheets หรือ Looker Studio เชื่อมต่อมายัง BigQuery ได้ โดยที่เครื่องมือเหล่านี้ก็เป็นเครื่องมือที่ใช้งานได้ฟรีไม่มีค่าใช้จ่ายใด ๆ
จาก Architecture ที่นำเสนอคิดว่าหลายคนพอที่จะเข้าใจและเห็นภาพมากขึ้นแล้ว ซึ่งอิงกับ Challenge ที่หลายองค์กรเจอคือ เราจะทำ CDC กับข้อมูลบน Oracle มายัง BigQuery ได้อย่างไร เพราะโดยปกติแล้วจะมีการจัดการ Data Pipeline ที่ซับซ้อน แต่ตรงนี้ต้องบอกเลยว่าสำหรับ Google Cloud แล้วง่ายนิดเดียว เรามาลองทำไปพร้อมกันด้วย Datastream
ขั้นตอนการทำ CDC จาก Oracle ไปยัง BigQuery
เพื่อความเข้าใจที่มากขึ้นขอเริ่มจากภาพรวมก่อนว่าเราจะมีขั้นตอนอะไรบ้าง
- ฝั่ง Oracle
- เตรียม Oracle Database ให้พร้อม
- Configure Archivelog บน Oracle Database เพื่อรองรับ CDC
- ฝั่ง Google Cloud
- สร้าง Connection Profiles บน Datastream
- Source Profile เป็น Oracle
- Destination Profile เป็น BigQuery
- สร้าง Streams บน Datastream
- Start Streams และดูผลลัพธ์บน BigQuery
- สร้าง Connection Profiles บน Datastream
จากขั้นตอนแล้วดูไม่ยากเลยใช่ไหม ซึ่งเราไม่จำเป็นต้องเขียนโค้ดเลย สำหรับ EP.2 เราจะมาเริ่มต้นการติดตั้ง Oracle เพื่อทดสอบไปพร้อมกัน
หากสนใจบริการต่าง ๆ หรือต้องการคำปรึกษาเพิ่มเติมติดต่อเรา
ได้ที่ marketing@tangerine.co.th หรือเบอร์ 02-285-5511
เพื่อรับคำตอบจากผู้เชี่ยวชาญที่ได้รับการรับรองมาตรฐานและมีประสบการณ์